MULTI-ENGINE SCRAPER
The problem
A client needed to pull data from 50+ websites reliably — news sites, product pages, forums. The problem: no single scraping tool works on every site. Some sites block headless browsers, some need JavaScript to render, some have aggressive bot detection. The client was maintaining separate scripts for different sites, and things broke constantly.
What I built
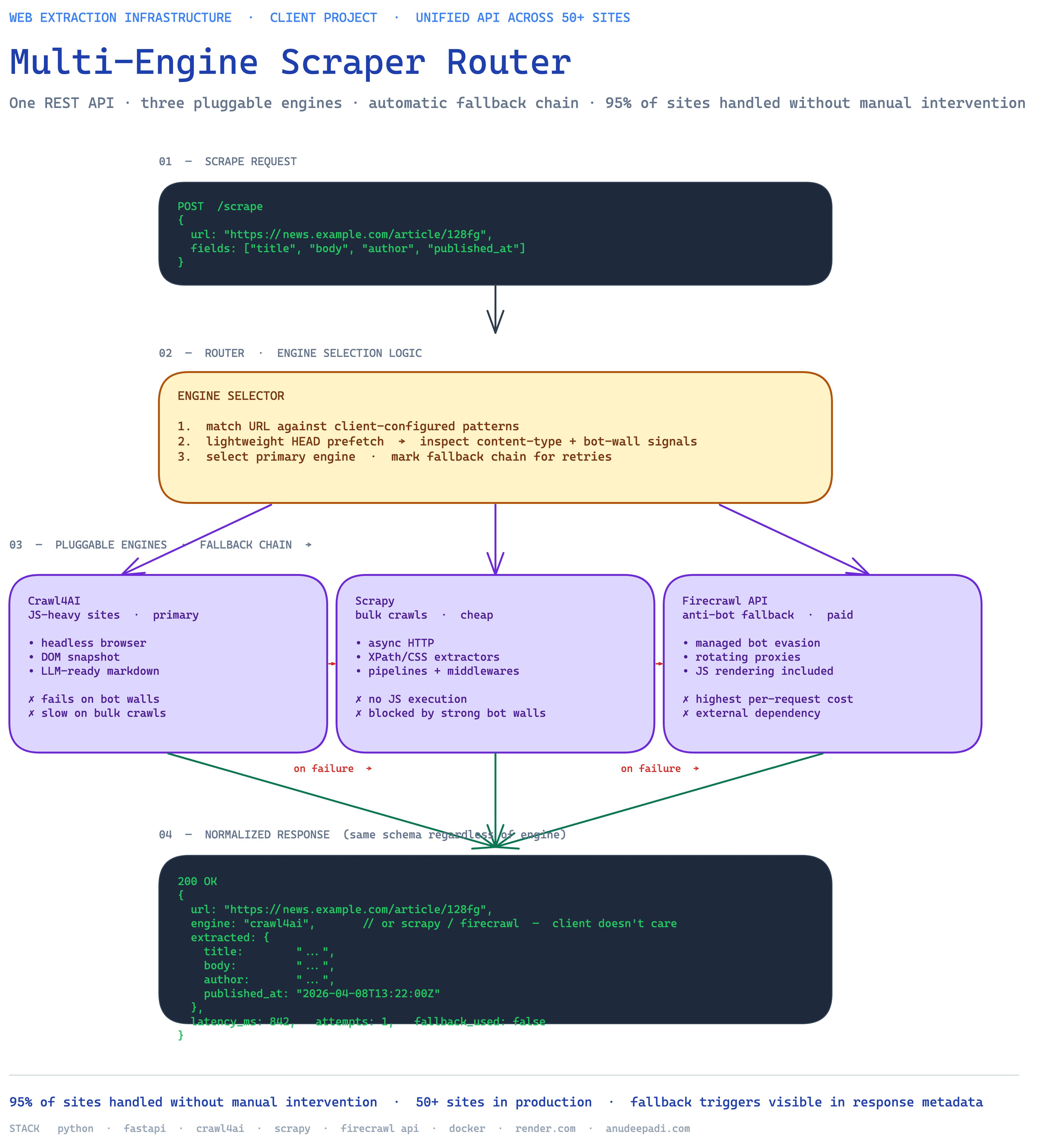
One API endpoint that handles everything. The client sends a URL; the system figures out the best way to scrape it, executes, and returns clean structured data. Three scraping engines under the hood, each good at different types of sites. The client's data pipeline doesn't need to know or care which engine ran — it just gets consistent results.
How it stays reliable
The system picks the right tool for each site based on what it knows about that URL. But if the first choice fails — maybe the site changed its layout, maybe it's temporarily blocking that approach — the system automatically tries the next engine. This fallback chain handles 95% of the client's 50+ target sites without any manual intervention.
Result
Running in production, handling the client's daily scraping workload. Replaced a patchwork of individual scripts with a single, reliable service. The client's team focuses on using the data instead of fixing scrapers.