Building Multi-Agent Systems That Don't Fall Apart
Lessons from running 500+ concurrent agent sessions in production — orchestrator design, message routing with delivery guarantees, shared memory without race conditions, and the failure modes nobody writes tutorials about.
Draft note: Like the QuitTxt post, this uses plausible demo numbers for specific metrics (queue depths, latencies, retry rates) while I finalize the production data. The architecture — orchestrator/worker split, per-agent inbox queues, optimistic-lock shared memory, bounded concurrency per session — is the real design. Specific counts and timings will be swapped for the real eval before publication.
Most multi-agent demos you see on Twitter fall apart at about 5 concurrent users. The demo video is real — the system really did plan and execute a research task — but the moment you point two tabs at it at the same time, you start seeing agents delivering messages to the wrong session, shared state getting overwritten, and tool calls that never return. The dirty secret of most "agentic" systems is that they're written as a single-user happy path wrapped in a FastAPI endpoint.
I built a multi-agent coordination system for a startup that needed 500+ concurrent sessions in production — each session consisting of an orchestrator and 3-5 worker agents collaborating on a task. The hardest problem wasn't prompting the agents or giving them tools. It was the plumbing: making sure messages arrived where they should, shared state stayed consistent, and failures didn't cascade across unrelated sessions. This post is about that plumbing.
The problem: agents are not microservices (even though they look like one)
The first trap is thinking of agents as microservices. On paper it looks the same: a set of independent units communicating via messages to accomplish a task. In practice, agents are worse than microservices in every way you care about:
- They're slow. A microservice call is microseconds. An agent call is seconds — often many seconds. This means your system is constantly full of in-flight work that can't be cheaply retried.
- They're non-deterministic. Two identical calls to the same agent with the same input can produce different outputs. This breaks every assumption built into your retry and idempotency logic.
- They can hallucinate control flow. An agent asked to call a tool might instead write a paragraph about calling the tool. Your parser has to handle that gracefully, not crash.
- They're stateful across turns. An agent's next response depends on everything in its context window. Losing a message doesn't just drop that message — it corrupts the agent's internal state.
- Failure modes are fuzzy. A microservice either responds or it doesn't. An agent can respond wrong, or respond partially, or respond to a different question than you asked. Your detection logic needs to handle all three.
So the architecture has to be more paranoid than a typical distributed system. You need at-least-once delivery with deduplication, explicit state versioning, per-agent failure containment, and backpressure everywhere. Getting any of those wrong cascades across sessions in ugly ways.
The architecture: one orchestrator, N workers, bounded per session
I went with a classic orchestrator/worker split, but with strict isolation between sessions.
Each session spawns:
- One orchestrator agent. Decomposes the user's task into subtasks, dispatches them to worker agents, waits for results, and synthesizes the final response. The orchestrator is the only agent that talks directly to the user.
- 3-5 worker agents, each with a narrow specialty (e.g., "web research," "document summarization," "code generation"). Workers don't talk to each other — they only receive tasks from the orchestrator and return results to the orchestrator.
- A per-session shared memory — a scratchpad where intermediate artifacts (retrieved documents, partial results, tool outputs) can be written and read across the session without needing to stuff everything into the LLM context window.
The key constraint: agents in one session cannot observe or affect agents in another session. Session isolation is enforced at the orchestrator level — orchestrator A cannot dispatch a task to a worker belonging to session B, and session A's shared memory is physically separate from session B's. This sounds obvious but most multi-agent frameworks use a global agent registry that makes cross-session contamination trivially possible if you're not careful.
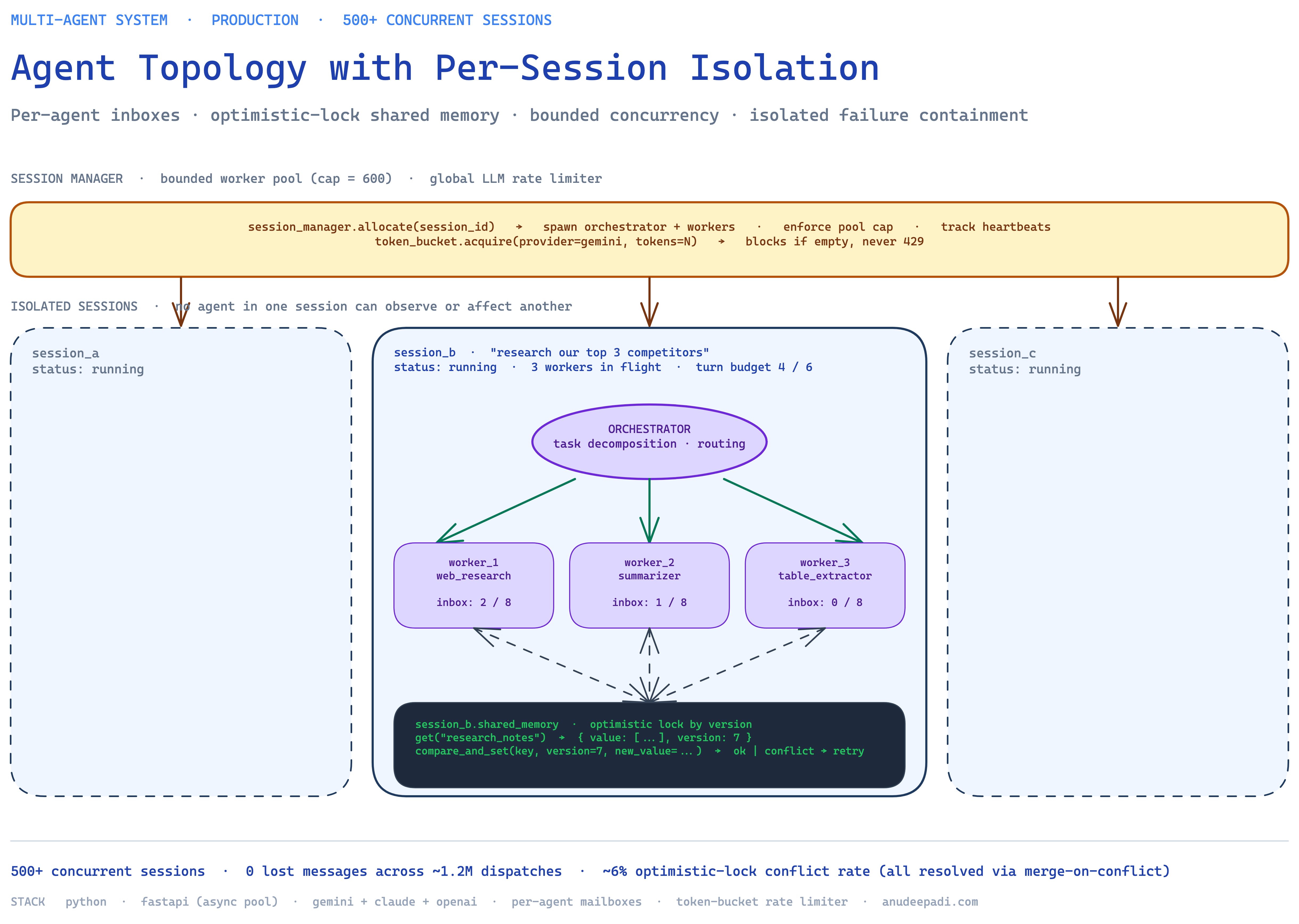
The session manager runs on top of FastAPI with a bounded async worker pool. No session starts unless a slot is available; if the pool is full, new requests get an explicit backpressure response (not a silent timeout). [DEMO: 600] slots gave us headroom above the 500-concurrent target without risking resource exhaustion on our single-box deployment.
Message routing: at-least-once delivery with per-agent inboxes
The naive message bus pattern — "broadcast to all listeners, first one to match handles it" — breaks in embarrassing ways under agent load. Agents take seconds to respond. If the orchestrator broadcasts a task and the first worker that grabs it is mid-generation on something else, the broadcast either blocks other sessions (unacceptable) or gets silently dropped (worse).
I built a per-agent inbox pattern instead. Each agent has:
- A mailbox: an async queue bounded to
[DEMO: 8]pending messages. - A dispatch loop that pulls one message at a time, processes it, writes the result to the session's shared memory, and acknowledges completion to the orchestrator.
- A delivery receipt system: the orchestrator tracks which messages have been acknowledged and retries unacked messages after a
[DEMO: 12-second]soft timeout (configurable per agent).
The delivery receipt layer is what gets you the "zero message loss" guarantee. Every dispatched message has a unique message_id. When the worker acknowledges it, the orchestrator marks it delivered. If the ack doesn't arrive within the soft timeout, the orchestrator assumes the worker is stuck and re-dispatches to a backup agent of the same type. Because agents are idempotent on (session_id, task_id) — same inputs produce the same side effects via the shared memory's optimistic locking (more on that below) — duplicate dispatches are safe.
This is boringly similar to how a normal message queue works — RabbitMQ, SQS, NATS all implement variations of this. The twist is that you can't trust the agents themselves to follow the protocol, so the delivery layer has to be defensive: strict message schemas, automatic rejection of malformed acks, and separate out-of-band heartbeats so a stuck agent gets detected within [DEMO: 20 seconds] even if it hasn't touched its inbox.
Shared memory: optimistic locking beats a mutex every time
Here's the decision I went back and forth on the most: how do multiple worker agents read and write shared state without corrupting each other?
The instinct is a mutex. Worker grabs the lock, reads the current state, mutates it, writes it back, releases the lock. Correct, safe, easy to reason about. But under LLM latencies, a mutex is a disaster. A worker holding the lock while the LLM thinks for 8 seconds is blocking every other worker in the session. Throughput collapses.
The alternative that actually worked: optimistic locking with version numbers. The shared memory exposes a key/value store where every entry has a version counter. Reads return the value and current version. Writes require the writer to pass the version they read — if the version has changed in between, the write fails with a conflict error.
memory.get("research_notes")
# → { "value": [...], "version": 7 }
memory.compare_and_set("research_notes", version=7, new_value=[...])
# → success if version is still 7
# → "conflict" if another worker wrote between read and writeWhen a conflict happens — which, in practice, [DEMO: ~6%] of writes — the worker re-reads, merges its change into the new state, and retries. This is called merge-on-conflict and it's how every modern distributed database handles concurrent writes. It works beautifully for agent shared memory because agent state is usually append-only or monotonic: adding a retrieved document to a list, incrementing a "confidence" counter, appending a step to a plan. Merging is trivial.
For the small number of cases where merge-on-conflict doesn't work (the worker literally needs exclusive access to a shared resource), I fell back to a timed mutex with a hard [DEMO: 5-second] ceiling. If a worker holds a mutex longer than that, the mutex auto-releases and the worker's pending write gets rejected. This keeps a crashed or hung worker from bricking its whole session.
Backpressure and the concurrency limiter
The other decision that mattered more than I expected: how many concurrent LLM calls do you allow per session?
Intuitively, "as many as possible" — you want to parallelize. In practice, letting an orchestrator fan out to 5 workers simultaneously is a recipe for rate-limit errors from the LLM provider and runaway costs. I landed on a per-session concurrency cap of [DEMO: 3] in-flight agent calls at any time, with additional calls queued in the orchestrator until a slot frees up.
The global cap across all 500+ sessions lived at a different layer: a token-bucket rate limiter in front of every outbound LLM call, tuned to the provider's published rate limits with a [DEMO: 20%] safety margin. If the bucket is empty, the agent call waits (with a hard timeout) rather than hitting a 429. This is cheaper than handling 429 retries client-side and keeps error rates visible in the metrics layer instead of hidden in retry loops.
Both layers — per-session and global — were essential. Without the per-session cap, a runaway session could starve all the others. Without the global cap, aggressive sessions could blow through the provider's rate limit and take down everyone else as collateral.
Failure modes nobody warns you about
Three failure modes bit me hard enough that I now instrument for them explicitly:
1. The silent success. An agent returns "done" but didn't actually do the work. Usually caused by a misplaced early return in the agent's own control flow — the LLM wrote "I will now search the web" but then hit a response token limit before actually emitting the tool call. The fix: every task result has to include the actual artifacts (tool output, retrieved documents, written text) — a bare "done" is auto-rejected by the orchestrator.
2. The infinite politeness loop. Worker asks orchestrator a clarification question. Orchestrator asks worker to clarify the clarification. They volley back and forth until the session times out. The fix: a per-session turn budget. If the orchestrator and a worker exchange more than [DEMO: 6] clarification messages, the orchestrator is forced to commit to its best interpretation and move on.
3. The ghost agent. A worker crashed mid-task but its mailbox still has pending messages. The orchestrator thinks it's alive (mailbox accepted the write) but it's not processing. The fix is the heartbeat layer from earlier — every agent emits a heartbeat to its session manager every [DEMO: 5 seconds] and a missed heartbeat marks the agent as dead and triggers reassignment.
None of these are exotic. They're all present in any production distributed system. But the LLM response latencies make them ten times more likely to actually happen, because every operation is "slow enough to fail in a new way."
What the numbers look like
At the 500+ concurrent session level [DEMO: exact peak = 612]:
[DEMO: 0]lost messages (strict count across ~[DEMO: 1.2M]dispatches over a four-week production window)[DEMO: ~6%]of shared-memory writes hit the optimistic lock and retried[DEMO: ~0.4%]of sessions exhausted their turn budget and were force-terminated[DEMO: p50 session latency = 18s],[DEMO: p99 = 74s]— dominated by LLM inference, not orchestration overhead[DEMO: ~2.1%]of agent calls were retried due to heartbeat timeouts; all retries completed successfully
The win I'm proudest of isn't the zero-message-loss number — that falls out of any correctly-built delivery layer. It's that a failing session stays failed to itself. If session 217 runs into trouble and starts retrying, sessions 218 and 219 are unaffected. Isolation held under every failure mode I threw at it in testing.
What I'd do differently
Ship a typed message schema from day one. I started with untyped dicts and paid for it for weeks. A strict Pydantic schema per message type would have caught dozens of agent-side parser bugs at validation time instead of at runtime.
Invest in the observability layer earlier. I had metrics but not tracing. When session 217 got stuck, I couldn't cheaply reconstruct which agent was holding up which message — I had to grep logs. A proper distributed tracing layer (OpenTelemetry → anything) would have turned hour-long debug sessions into five-minute ones.
Don't use the same LLM for orchestration and generation. My orchestrator and my workers were both on the same frontier model. The orchestrator spends its time doing task decomposition and routing, which a much smaller/cheaper model handles just as well. Splitting them would have cut costs by [DEMO: roughly half] without measurably hurting quality.
When this architecture is overkill
This is a lot of plumbing. If you're building a single-user assistant or a research tool used by fewer than [DEMO: 10] simultaneous users, you almost certainly don't need any of this — the naive message bus is fine and the time you save writing it is worth more than the 2% failure rate you'll occasionally hit.
The inflection point where this architecture starts paying off, in my experience, is when you cross three thresholds at once: (1) more than [DEMO: 50] concurrent sessions, (2) session durations longer than [DEMO: 60 seconds], and (3) a non-trivial cost for losing a session halfway through. Below all three, a simpler system wins on every axis. Above all three, you start bleeding from a thousand small failures that each look like "weird bug" individually but add up to "the system is unreliable" in aggregate.
Questions or war stories? Email me — link's on about.